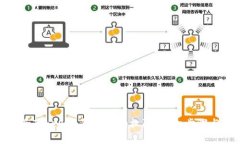
引言 随着加密货币的迅猛发展,越来越多的用户希望能够将其虚拟货币转换为现实中的现金。Tokenim作为一个新兴的加...
Tokenization是将数据分解为更小、可管理的部分(称为“token”)的过程,这一过程在自然语言处理、数据安全和各种编程领域中都非常常见。在Android开发中,Tokenization尤其重要,尤其是在处理用户输入、文本分析及数据交换时。它能够帮助程序更有效地理解和处理信息,提高数据处理效率和安全性。

在Android应用中,Tokenization提供了多种优势。首先,用户输入的信息往往需要被分解成逻辑单元,便于进一步分析或存储。例如,在一个聊天应用中,用户的消息可以被拆分为单词或短语,以便进行关键词搜索或情感分析。此外,Tokenization还能够提升数据的安全性。例如,当应用需要传输敏感信息时,将其分解为token可以减少数据在传输过程中被恶意获取的风险。在大数据分析中,对用户行为的Tokenization处理也可以帮助识别模式和趋势,提升用户体验。
在Android中实现Tokenization的第一步就是选择适合的编程语言和工具。大多数情况下,Java或Kotlin被广泛用于Android开发。在开始实际编码之前,开发者需了解Tokenization的基本概念及其应用场景。
接下来的步骤包括设定Token的定义标准。比如,如果你正在处理一个文本输入框,可能希望按空格或者标点符号来划分Token。接着,可以使用自己的算法或现成的库,比如Apache Commons Lang中的StringUtils类,来实现Tokenization。
最后,确保对token的处理方式进行有效的错误处理和异常捕获,以保证应用的稳定性。这些细节将直接影响用户的使用体验。

以下是一个简单的Tokenization示例代码,利用Java实现。通过这个范例,开发者可以对Tokenization的实现有更深刻的理解:
String text = "Hello, welcome to the world of Android development!";
String[] tokens = text.split("\\s |[,!.?] "); // 通过空格或标点符号进行分割
for(String token : tokens) {
System.out.println(token);
}
以上代码将会分解输入文本为多个token,并通过遍历的方式输出每个token。这种基本的Tokenization很适合用作简单的数据分析。同样的逻辑也可以适用于更复杂的应用,例如文本情感分析或搜索引擎。
Tokenization和词法分析通常被混淆,但它们在处理数据时有本质的区别。Tokenization是将输入的字符串分割成一个个独立的token,而词法分析则是在给定的token上执行更深入的分析,通常用于编译器的前期阶段。词法分析不仅仅依赖于分割,还会分析token的类别和语法结构,为后续的语法分析做准备。在Android开发中,Tokenization的实用性更广,因为应用程序往往需要处理用户输入,而不仅仅是编译源代码。
处理多语言文本的Tokenization是一项挑战,因为不同的语言有不同的结构和分割规则。在Android中,可以使用Unicode字符集,对字符进行编码,识别方言特性和常用标点符号。例如,中文、日文和韩文并没有空格,这就意味着必须实现特定的分词工具,如HanLP或IKAnalyzer。这些工具能帮助开发者在实现Tokenization时满足不同语言的需求,避免简单的字符分割导致语义不清的问题。
性能是实现Tokenization时的重要考虑因素。要提升Tokenization的速度,可以考虑以下方法:首先,使用正则表达式时,减少复杂的模式,确保匹配规则尽量简单,可以提升速度。其次,在应用中避免重复的Tokenization操作,尤其是在用户频繁输入时。另外,开发者可以使用非阻塞的异步调用,将Tokenization工作移至后台线程中处理,确保界面流畅。此外,缓存已处理的文本也能够大幅提高后续Tokenization的效率。
在机器学习中,Tokenization是自然语言处理(NLP)工作的基础。通过Tokenization,文本数据可以被清洗并转换为结构化信息,便于机器学习算法处理。在训练模型之前,开发者常常需要对文本数据进行Tokenization处理,以便提取特征、进行分类或聚类等任务。而在具体实现中,Tokenization能够帮助识别信息的先后顺序、上下文关联,以及重要的关键词,从而提升模型的识别能力和准确度。
在Android开发中,有多种现成的Tokenization库可供使用。一些常用的库包括:Apache Lucene,它提供了一组强大的文本分析和Tokenization功能;Stanford NLP,它是一个全面的自然语言处理工具,支持多种语言的Tokenization;以及Google的Tango,它的Tokenization库可以高效地处理不同格式的文本。这些库都经过广泛的测试和,能够帮助开发者更轻松地实现Tokenization功能。
Tokenization不仅在数据处理上起着重要作用,还能够显著提升数据安全级别。在金融行业,Tokenization被广泛应用于保护用户的信用卡信息,通过将敏感数据组合成不可识别的token,确保在传输过程中的机密性。在Android应用中,开发者可以结合加密技术和Tokenization,将敏感信息分解成token,并在传输时进行加密的处理,从而最大限度降低数据外泄的风险,提高用户信任度和应用的安全性。


引言 随着加密货币的迅猛发展,越来越多的用户希望能够将其虚拟货币转换为现实中的现金。Tokenim作为一个新兴的加...

Tokenim手机软件概述 在数字货币和资产管理逐渐受到重视的今天,Tokenim手机软件应运而生。Tokenim是一款专注于数字资...
一、Tokenim助记词的概述 在加密货币的世界中,助记词是保护用户资金的关键概念。Tokenim是一款流行的加密货币钱包...

在当今数字经济快速发展的背景下,Tokenim作为一个新兴的数字资产交易平台,逐渐引起了广泛关注。Tokenim不仅仅是一...